Deploy fastai — Transformers based NLP models using Amazon SageMaker and Creating API using AWS API Gateway and Lambda function.

Table of Contents
- 1. Introduction
- 2. Part 1 — Exporting model and reloading it
- 3. Part 2 — Deployment using Amazon SageMaker
- 4. Part 3 — Creating Model API using Amazon Lambda and Amazon API Gateway
- Conclusion
- References
1. Introduction
The transformers library is created by Hugging Face. Formerly known as pytorch-transformers or pytorch-pretrained-bert, this library brings together over 40 state-of-the-art pre-trained NLP models (BERT, GPT-2, RoBERTa, CTRL…). It’s an opinionated library built for NLP researchers seeking to use/study/extend large-scale transformers models.
The implementation gives interesting additional utilities like tokenizer, optimizer or scheduler. It can be self-sufficient, but incorporating it within the [fastai](https://docs.fast.ai) library provides simpler implementation compatible with powerful fastai tools like Discriminate Learning Rate, Gradual Unfreezing or Slanted Triangular Learning Rates. The point here is to get easily state-of-the-art results and to “make NLP uncool again”.
I suppose that you already implemented your model, and I am not going to cover this part, the article will tackle only the deployment part using AWS services, but if you need to see an implementation check this Kernel on Kaggle.
2. Part 1 — Exporting model and reloading it
2.1. Exporting the model
First, we need to export our model as a PKL file using the learner module of the fastai library :
learner.export('models/fastai_transformers_model.pkl')
2.2. Loading the model :
When using a custom transformers model such as Bert, you need to redefine the architecture of the custom model, so that when loading it the load_learner() function will look for that specific function to use on new predictions.
Before loading the model, we need to redefine the custom transformer model that we used on training.
from transformers import BertTokenizer
from transformers import PreTrainedModel
from fastai.text import *
class FastAiBertTokenizer(BaseTokenizer):
"""Wrapper around BertTokenizer to be compatible with fast.ai"""
def __init__(self, tokenizer: BertTokenizer, max_seq_len: int=128, **kwargs):
self._pretrained_tokenizer = tokenizer
self.max_seq_len = max_seq_len
def __call__(self, *args, **kwargs):
return self
def tokenizer(self, t:str) -> List[str]:
"""Limits the maximum sequence length"""
return ["[CLS]"] + self._pretrained_tokenizer.tokenize(t)[:self.max_seq_len - 2] + ["[SEP]"]
class CustomTransformerModel(nn.Module):
def __init__(self, transformer_model: PreTrainedModel):
super(CustomTransformerModel,self).__init__()
self.transformer = transformer_model
def forward(self, input_ids):
# Return only the logits from the transfomer
logits = self.transformer(input_ids)[0]
return logits
Then we can load our model and make predictions :
learner = load_learner(Path(ROOT_PATH),'fastai_transformers_model.pkl')
outputs = learner.predict("a text to predict or whatever")
3. Part 2 — Deployment using Amazon SageMaker
In Amazon’s own words:
Amazon SageMaker provides every developer and data scientist with the ability to build, train, and deploy machine learning models quickly. Amazon SageMaker is a fully-managed service that covers the entire machine learning workflow to label and prepare your data, choose an algorithm, train the model, tune and optimize it for deployment, make predictions, and take action. Your models get to production faster with much less effort and lower cost.
SageMaker provides a framework to both training and deploying your models. Everything is run in Docker containers.
since we will use Amazon SageMaker Python SDK, we need a notebook instance to run our code.
3.1. Using SageMaker Python SDK to deploy the model
from the SageMaker Python SDK documentation :
Amazon SageMaker Python SDK is an open source library for training and deploying machine-learned models on Amazon SageMaker. With the SDK, you can train and deploy models using popular deep learning frameworks, algorithms provided by Amazon, or your own algorithms built into SageMaker-compatible Docker images.
3.1.1. Prepare the environment
The general architecture of the deployment is as follows :
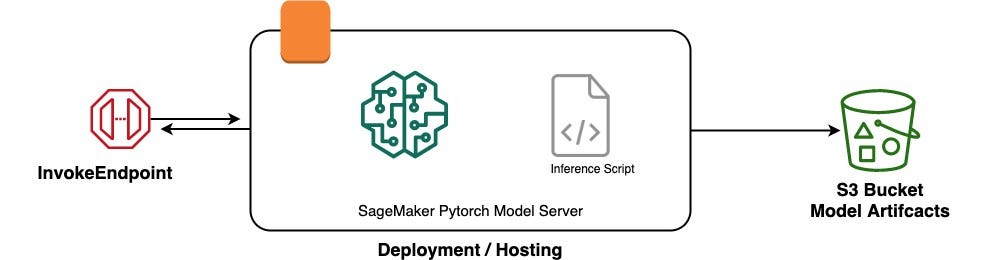
after uploading your model ( PKL file ) to the notebook instance, we need to zip it up so that we can upload it to S3.
import tarfile
with tarfile.open('model.tar.gz', 'w:gz') as f:
t = tarfile.TarInfo('models')
t.type = tarfile.DIRTYPE
f.addfile(t)
f.add('fastai_transformers_model.pkl', arcname='fastai_transformers_model.pkl')
Then we can upload it to S3 storage as follows :
import sagemaker
from sagemaker.utils import name_from_base
sagemaker_session = sagemaker.Session()
bucket = sagemaker_session.default_bucket()
prefix = f'sagemaker/{name_from_base("fastai-transformers-model")}'
model_artefact = sagemaker_session.upload_data(path='models/model.tar.gz', bucket=bucket, key_prefix=prefix)
Now we are ready to deploy our model to the SageMaker model hosting service. We will use the SageMaker Python SDK with the Amazon SageMaker open-source PyTorch container as this container has support for the fast.ai library. Using one of the predefined Amazon SageMaker containers makes it easy to write a script and then run it in Amazon SageMaker.
To serve models in SageMaker, we need a script that implements 4 methods: model_fn, input_fn, predict_fn & output_fn.
-
The model_fn method needs to load the PyTorch model from the saved weights from the disk.
-
The input_fn method needs to deserialize the invoke request body into an object we can perform prediction on.
-
The predict_fn method takes the deserialized request object and performs inference against the loaded model.
-
The output_fn method takes the result of prediction and serializes this according to the response content type.
The methods input_fn and output_fn are optional and if omitted SageMaker will assume the input and output objects are of type NPY format with Content-Type application/x-npy.
This is the serve.py script :
import logging, requests, os, io, glob, time
import json
from transformers import BertTokenizer
from transformers import PreTrainedModel
import torch
from fastai.text import *
logger = logging.getLogger(__name__)
logger.setLevel(logging.DEBUG)
JSON_CONTENT_TYPE = 'application/json'
#redefining transformers custom model
class CustomTransformerModel(nn.Module):
def __init__(self, transformer_model: PreTrainedModel):
super(CustomTransformerModel,self).__init__()
self.transformer = transformer_model
def forward(self, input_ids):
# Return only the logits from the transfomer
logits = self.transformer(input_ids)[0]
return logits
class FastAiBertTokenizer(BaseTokenizer):
"""Wrapper around BertTokenizer to be compatible with fast.ai"""
def __init__(self, tokenizer: BertTokenizer, max_seq_len: int=128, **kwargs):
self._pretrained_tokenizer = tokenizer
self.max_seq_len = max_seq_len
def __call__(self, *args, **kwargs):
return self
def tokenizer(self, t:str) -> List[str]:
"""Limits the maximum sequence length"""
return ["[CLS]"] + self._pretrained_tokenizer.tokenize(t)[:self.max_seq_len - 2] + ["[SEP]"]
# loads the model into memory from disk and returns it
def model_fn(model_dir):
logger.info('model_fn')
path = Path(model_dir)
learn = load_learner(model_dir, 'fastai_transformers_model.pkl')
return learn
# Perform prediction on the deserialized object, with the loaded model
def predict_fn(input, model):
logger.info("Calling model")
start_time = time.time()
pred_class,pred_idx,pred_values = model.predict(input)
print("--- Inference time: %s seconds ---" % (time.time() - start_time))
# print(f'Predicted class is {str(pred_class)}')
#print(f'Predict confidence score is {predict_values[predict_idx.item()].item()}')
return json.dumps({
"input": input,
"pred_class": str(pred_class),
"pred_idx":sorted(
zip(model.data.classes, map(float, pred_idx)),
key=lambda p: p[1],
reverse=True
),
"predictions": sorted(
zip(model.data.classes, map(float, pred_values)),
key=lambda p: p[1],
reverse=True
)
})
# Deserialize the Invoke request body into an object we can perform prediction on
def input_fn(request_body, content_type=JSON_CONTENT_TYPE):
logger.info('Deserializing the input data.')
# process an jsonlines uploaded to the endpoint
if content_type == JSON_CONTENT_TYPE: return request_body["text"]
raise Exception('Requested unsupported ContentType in content_type: {}'.format(content_type))
# Serialize the prediction result into the desired response content type
def output_fn(prediction, accept=JSON_CONTENT_TYPE):
logger.info('Serializing the generated output.')
if accept == JSON_CONTENT_TYPE: return json.dumps(prediction), accept
raise Exception('Requested unsupported ContentType in Accept: {}'.format(accept))
one other thing is to put this script inside a folder and call it my_src, and we will add a requirements text file; to force SageMaker to install the required library such as Fastai.
my requirements.txt file contains only this :
fastai==1.0.52
transformers
you can read much about this on the SageMaker Python SDK documentation here.
3.1.2. Deploy the model :
First, we need to create a RealTimePredictor class to accept JSON/application item as input and output JSON. The default behavior is to accept a NumPy array.
from sagemaker.predictor import RealTimePredictor, json_deserializer
class Predictor(RealTimePredictor):
def __init__(self, endpoint_name, sagemaker_session):
super().__init__(endpoint_name, sagemaker_session=sagemaker_session, serializer=None,
deserializer=json_deserializer,content_type='application/json')
We need to get the IAM role ARN to give SageMaker permissions to read our model artefact from S3.
import sagemaker
role = sagemaker.get_execution_role()
we will deploy our model to the instance type ml.p2.xlarge . We will pass in the name of our serving script e.g. serve.py. We will also pass in the S3 path of our model that we uploaded earlier.
from sagemaker.pytorch import PyTorch, PyTorchModel
model=PyTorchModel(model_data=model_artefact, name=name_from_base("fastai-transformers-model"),
role=role, framework_version='1.4.0', entry_point='serve.py', predictor_cls=Predictor,source_dir='my_src')
predictor = model.deploy(initial_instance_count=1, instance_type='ml.p2.xlarge')
It will take a while for SageMaker to provision the endpoint ready for inference.
3.2.3. Calling Endpoint using Boto3 :
Boto is the Amazon Web Services (AWS) SDK for Python. It enables Python developers to create, configure, and manage AWS services, such as EC2 and S3. Boto provides an easy-to-use, object-oriented API, as well as low-level access to AWS services.
import boto3
import json
client = boto3.client('sagemaker-runtime')
response = client.invoke_endpoint(
EndpointName='your_endpoint_name',
Body="testing the model",
ContentType='application/json',
Accept="application/json"
)
result = response['Body'].read().decode()
4. Part 3 — Creating Model API using Amazon Lambda and Amazon API Gateway
We will invoke our model endpoint deployed by Amazon SageMaker using API Gateway and AWS Lambda.
The following diagram shows how the deployed model is called using a serverless architecture. Starting from the client-side, a client script calls an Amazon API Gateway API action and passes parameter values. API Gateway is a layer that provides API to the client. In addition, it seals the backend so that AWS Lambda stays and executes in a protected private network. API Gateway passes the parameter values to the Lambda function. The Lambda function parses the value and sends it to the SageMaker model endpoint. The model performs the prediction and returns the predicted value to AWS Lambda. The Lambda function parses the returned value and sends it back to API Gateway. API Gateway responds to the client with that value.

4.1. Create Amazon Lambda Function
AWS Lambda is an event-driven, serverless computing platform provided by Amazon as a part of Amazon Web Services. It is a computing service that runs code in response to events and automatically manages the computing resources required by that code.
To create a function we specify its name and the Runtime Environment (Python 3 in our case) :
Then we use our custom function to call endpoint using Boto3 library as follows :
import os
import io
import boto3
import json
import csv
# grab environment variables
ENDPOINT_NAME = "fastai-transformers-model"
runtime= boto3.client('runtime.sagemaker')
def lambda_handler(event, context):
print("Received event: " + json.dumps(event, indent=2))
data = json.loads(json.dumps(event))
payload = data['body']
response = runtime.invoke_endpoint(EndpointName=ENDPOINT_NAME,
ContentType='application/json',
Body=payload)
result = json.loads(response['Body'].read().decode())
#print(result)
return result
4.2. Creating Amazon Web API Gateway instance :
Amazon API Gateway is a fully managed service that makes it easy for developers to create, publish, maintain, monitor, and secure APIs at any scale.
We create an API and associate it to Lambda function as an Integration as follows :
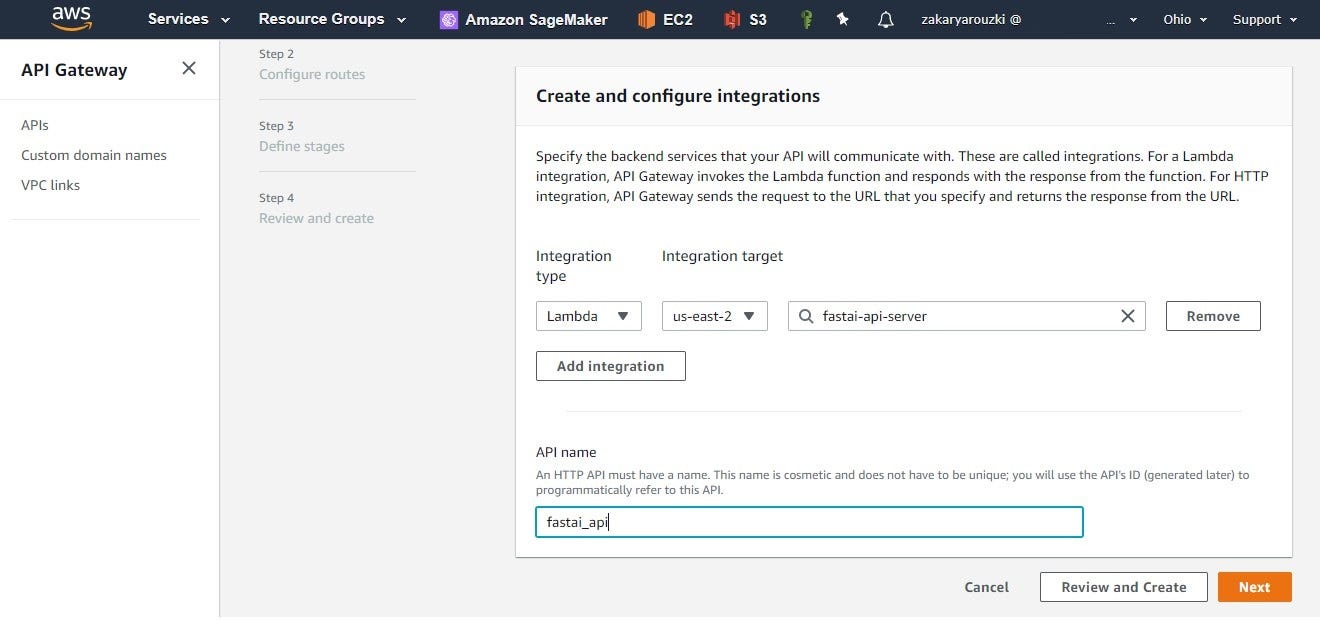
then we need to identify the routes of our API, we will use just one route “/classify” and the “POST” as our Request Method.

4.3. Testing your Amazon API
Now that we have the Lambda function, an API Gateway, and the test data, let’s test it using Postman, which is an HTTP client for testing web services.
When we deployed your API Gateway, it provided the invoke URL that looks like:
https://{restapi_id}.execute-api.{region}.amazonaws.com/{stage_name}/{resource_name}
In Postman we place the Invoke URL and we choose POST as the method of request. In the Body tab, we place the text to classify as shown in the following screenshot.
Then we send our requests and it will return JSON item as a response containing prediction of the model.

We can also use the requests library in python as follows :
import requests
import json
url = "https://api_id_here.execute-api.us-east-2.amazonaws.com/test/classify"
payload = "\"your text here! \""
headers = {
'Content-Type': 'application/json',
}
response = requests.request("POST", url, headers=headers, data = payload)
print(json.loads(response.text.encode('utf8')))
Conclusion
That is it. You have created a model endpoint deployed and hosted by Amazon SageMaker. Then you created serverless components (an API Gateway and a Lambda function) that invoke the endpoint. Now you know how to call a machine learning model endpoint hosted by Amazon SageMaker using serverless technology.